Student Research | Real-Time Human Activity Classification in Videos
By Daniel Lütolf-Carroll and Rishabh Joshi, both Class of 2018
This excerpt is taken from an MSiA student research blog posting. Each month, students in our program submit original extracurricular research as part of our blog competition. The winner(s) are published to the MSiA Student Research Blog, our program website, and receive a chance to attend an analytics conference of their choice. Visit our blog to see more.
PROBLEM STATEMENT
Deep Learning has been applauded for its versatility and applicability on many use-cases across industries. We set out to explore and familiarize ourselves with DL on a problem that was relatable to most: video streaming. Our project aimed to enhance the user viewing experience by improving advertisement allocation to videos through activity classification of segments within a video. The underlying assumption is that users viewing a video centered around a human-relatable activity are often interested in the context, information, or even industry pertaining to the activity and would be receptive to advertisements associated with the activity.
The focus of our classification was therefore on isolated activities within a video. Our approach involved classifying images at a frame level, while also exploring ways of incorporating temporal information from the frames, so that advertisement can be fine-tuned even for videos with complex activities or a variety of themes that evolve over time. We developed deep learning models following different strategies to see what works best for identifying activities in videos.
DATASET
The dataset used is the UCF101 (crcv.ucf.edu/data/UCF101.php) from University of Central Florida Center of Research in Computer Vision. The dataset is composed of 13,320 videos labeled in 101 action categories of 5 types: Human-Object Interaction, Body-Motion Only, Human-Human Interaction, Playing Musical Instruments, and Sports. Figure 1 shows the classes of activities.
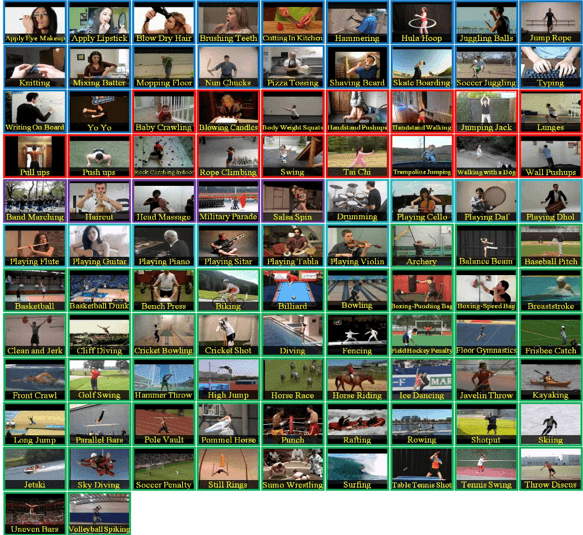
Figure 1. Classes of UCF-101 data
Most videos are between 4-10 seconds long and present an ideal training set to generate models that can capture individual actions. Although the videos vary in terms of quality, background, lighting and other contextual variations, the labeled activity category they belong to is well defined. After examining the dataset closely, our group decided that the UCF101 contains the ideal balance between strong features for activity classification of a video with enough noise and variation to be generalizable to other YouTube or online streaming videos. Videos are about 320×240 in resolution with 25fps (total bitrate ~340kbps) and are representative of the low quality frequently found online. However, in terms of visual information from the perspective of a human, there is little difference between a 1080p or 240p video for the sake of recognizing the contained activity, so the resolution was considered adequate for the project’s scope.
For each activity category there are 25 groups of videos, each representing a set of videos spliced from an original. Therefore, videos in the same group will have similar contextual variations (e.g. same background, actor, angle, lighting). Figure 2 shows examples of fencing and drumming images extracted from the training set.

Figure 2. Examples of frame images for Fencing and Drumming
Overall, our team was strongly satisfied with the dataset, given its diverse set of actions taken from daily unconstrained environments. Each action in the dataset is taken from different angles, giving us more power to correctly predict movements and actions in a realistic setting. This allowed us to evaluate the model using videos we recorded personally.
